この記事は、Web Accessibility Advent Calendar 2015、4日目の記事です。
Web Accessibility Advent Calendar に参加するのは初めてなので、自己紹介をします。
広島出身、東京と京都を経て、現在また広島在住。
2012年4月から NVDA 日本語チーム の代表としてオープンソースの Windows 用スクリーンリーダー NVDA の翻訳と日本語版開発を担当しております。
今年の夏 AccSell ポッドキャスト 第75回に出演して喋ったので、よろしければ聞いてみてください。
非営利法人 ATDO(支援技術開発機構)主任研究員として電子書籍のアクセシビリティ(EPUBやDAISY)に従事することもあります。
Web アクセシビリティに関することでは、今年から WAIC WG2(ウェブアクセシビリティ基盤委員会 実装ワーキンググループ)に参加しています。
NVDA の開発に Python が使われているというつながりで、広島で Python のイベント PyCon mini Hiroshima の実行委員長をやりました。
その他の仕事としては、某ステルスモードのスタートアップでソフトウェア開発に従事しています。
この記事では今年ポッドキャストやイベントで喋り足りなかった NVDA の実情をまとめてみたいと思います。
まず、ユーザー数や市場占有率について。
日本でよく参照されている「視覚障害者の携帯電話・スマートフォン・タブレット・ パソコン利用状況調査 2013」(新潟大学)によると、スクリーンリーダー利用者全体における NVDA 利用者の割合は6パーセントとされています。
このことから「NVDA でしかちゃんと動かないWeb標準を実装しても、大半の視覚障害ユーザーには届かない」と判断されがちです。
私は、話はそれほど単純ではないだろうと考えています。
理由のひとつは、この調査が実施された2013年秋から現在までに、NVDA 日本語版のユーザーはおそらく2倍以上に増えているであろうこと。
もうひとつは、同じくこの2年のあいだに「視覚障害者の Windows 離れ」が進んだと思われること、です。
まずは NVDA 日本語版の普及状況から。
NVDA には「更新の自動チェック」機能があり、24時間ごとにサーバーと通信をしています。
サーバー側で「自動チェック」のアクセス数を数えることで、1日ごとのユーザー数を把握しています。
ちなみに NVDA 本家版のユーザー数調査結果によると、1日あたり平均23775人が一番新しい数字になっています。
(1週間のアクセス数を1日平均に直しているのは、曜日によってユーザー数が異なるからでしょう。詳しくは後述)
NVDA 日本語版は2013年12月15日にリリースした 2013.3jp から、更新チェックを独自に運用していて、NVDA 日本語チームのサーバーでアクセスを数えています。
2014年1月5日ごろの1日あたりの平均ユーザー数は64人ですが、これは 2013.3jp よりも古いバージョンを把握できていないので、すこし控えめな数字になっているはずです。
その後、2014年3月20日に 2014.1jp を、6月2日に 2014.2jp をリリースしました。
大半のユーザーが 2013.3jp 以降を使っていると考えられる2014年5月上旬で、NVDA 日本語版の1日平均ユーザー数は176人でした。
そして2015年12月上旬、現在の1日平均ユーザー数は424人になっています。
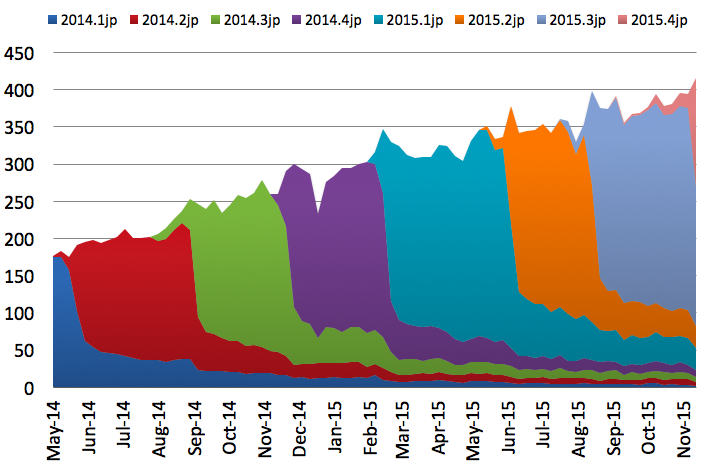
単純に伸び率を掛けると、6パーセントだったシェアは少なくとも15パーセントにはなっているでしょう。
一方で、パソコンを利用する視覚障害者、つまりこのシェア計算の母数は、この2年でどうなっているでしょうか。
はっきりとは分かりませんが、私は「期待したほど NVDA 日本語版のユーザー数が増えていない」ことと、視覚障害者コミュニティの「空気の変化」から判断して、「日常的なコミュニケーションや情報アクセスは iPhone の VoiceOver でやってしまう」というライフスタイルが急速に広まりつつあると感じています。
ひとつの根拠は、NVDA 日本語版のユーザー数が2014年年末から2015年年始にかけての1週間に大きく落ち込んだ、というデータです。
また、今回この記事を書くために、この3週間くらいの曜日ごとのユーザー数を調べてみたのですが、やはり土曜日と日曜日のユーザー数が少ない、という結果になりました。

視点を変えると、日本における NVDA は「日常生活を支援する道具」の座をスマートフォンに明け渡しつつあるかわりに、平日に職場で使われる「視覚障害者の就労支援ツール」になりつつある、という可能性を感じています。
就労における NVDA というテーマでは、今年9月のイベントでも IT 技術者として働いている NVDA ユーザーによる発表がありました。
また技術者ではない人からも、マッサージの仕事の予定管理にイントラネットが使われていて、そのWebサイトにアクセスするときに NVDA を使う、といった話を聞いたことがあります。
日本盲人職能開発センター(東京都新宿区)ではNVDAの講習会が定期的に開催されているようです。
(私は2014年の秋にこの施設で最初のNVDA講習会をお手伝いしました)
何度か書いたり喋ったりしたことですが、NVDA は「スクリーンリーダーの本来果たすべき役割分担」に忠実な、初心者には取っつきにくい、不親切なスクリーンリーダーです。
しかしそれはベンダーや開発者に「Web標準への準拠」「アクセシビリティAPIへの準拠」を促すための NVDA の戦略によるものです。
また一方で、たった2人のコア開発者が膨大な開発を効率よく行うための、プロジェクト生き残りの手段であるとも言えます。
NVDA の強みを手短に語ってほしい、NVDA でなければできない作業をアピールしてほしい、と言われるたびに複雑な気持ちになります。
正しく迅速に「標準」に準拠するスクリーンリーダーよりも、「特定のコンテンツやアプリケーションに特化したスクリーンリーダー」のほうが、どうしても「すごいソフトウェア」「お金を払うに値する製品」に見えてしまうのです。
開発中のアプリやコンテンツが NVDA でちゃんと動くようにするにはどうしたらいいか、という質問も、似たような状況です。
「特定のスクリーンリーダーに特化したコンテンツやアプリケーション」の開発を促したくない、ということも NVDA のポリシーだからです。
NVDA 本家の開発は最近、GitHub に移行しました。
この GitHub Issues では WAI-ARIA をどう解釈して NVDA でどう実装しているのか、といったやりとりも 頻繁に 交わされています。
NVDA に関わる前から「アクセシビリティ」にこだわっていた私にとって、アクセシビリティとは「物事の本質」であり「コンテンツの品質」であり「イノベーションの源泉」です。
日本では Web アクセシビリティのコミュニティにとっても、スクリーンユーザーのコミュニティにとっても NVDA はまだまだメジャーな存在ではありません。
Web アクセシビリティは「情報産業というエコシステムの傍流」かも知れませんが、しかし「技術ロードマップのど真ん中」だと信じています。
開発者とユーザーがお互いに「Web標準を考慮して頑張っても、相手が使いこなせないから無駄」と思うのではなく、双方が「互いに歩み寄れる妥協点」を見つけてほしいと思っています。
日本のユーザーに NVDA をリアルタイムに届けることで、まもなく始まるであろう「合理的配慮」をめぐる当事者たちと事業者たちの「戦い」を支えたいと考えています。
告知:
2016年1月9日(土曜)に大阪で開催される LibreOffice mini Conference 2016 Japan に参加します。
それから1月16日(土曜)に東京で(久しぶりの) NVDA ミートアップを開催します。
NVDA について質問したい人、一緒に NVDA コミュニティを盛り上げたい人のご参加をお待ちしております。

nishimotzの日記
-
スクリーンリーダー NVDA 日本語版の現状
-
OSC広島, DB勉強会
9月19日 オープンソースカンファレンス 2015 Hiroshima にNVDAユーザ会広島として出展しました。
オープンソースカンファレンス2015 Hiroshima #nvdajp #osc15hi
Posted by Masataka Shinke on 2015年9月19日
今年はセミナーの時間を作らず、出展だけにしました。
そのかわりに NVDA日本語版 のサイトに 開発者のためのNVDA というページを作りました。
アクセシビリティのチェックのために NVDA を使ってみたい、というかたに向けて、9月13日に東京で開催した講習会「Web制作者のためのNVDA入門」の資料をまとめて、最低限知っていただきたいインストールのコツなどを書いています。
聞きに行ったセッションではOSC広島特別企画「IT企業で働くということ」と題して行われたパネルディスカッションが盛り上がっていました。
学生時代に広島の勉強会コミュニティで活躍してくださり、社会人になった若手の人たちが登壇。OSC広島地元企画の若手社会人によるパネルディスカッションです。満員御礼ですね。 #osc15hi pic.twitter.com/bqaRYKNxIa
— OSC【公式】 (@OSC_official) 2015, 9月 19
ライトニングトーク&閉会式で、PyCon mini Hiroshima (11月22日)の告知をしました。
この日はサイトしか紹介できませんでしたが、本日 connpass での参加者・発表者の募集も開始しました。
翌日の9月20日は同じ場所で第11回中国地方DB勉強会に参加。
自分はデータベースに関しては「自分の技術レベルを自覚する」ために勉強会に来ているという感じでしょうか。。
技術的な話、技術者が意識するべきビジネスの話、勉強会コミュニティを通じて人脈や仕事を得たり成長したりする話、など、幅広く盛りだくさんでした。
懇親会の「町家風古民家で穴子料理」がなかなか良い雰囲気でした。 -
NVDA 2015.3jp と NVDA ワールド 2015 東京 (9月12日)
NVDA 日本語チームから NVDA 2015.3jp のリリース、そして NVDA ワールド 2015 東京 (9月12日) の最新情報です。
無料(オープンソース)の Windows 用スクリーンリーダー NVDA (NonVisual Desktop Access) の日本における開発コミュニティである NVDA 日本語チームは、2015年8月25日に NVDA 2015.3jp をリリースしました。
ダウンロード
http://i.nvda.jp/
NVDA日本語版 ダウンロードと説明
https://www.nvda.jp/
Windows 10, 8.1, 8, 7, Vista, XP(SP3) の32ビット版および64ビット版に対応しています。
Windows 8 以降ではタッチ操作が利用できます。
NVDA 日本語版のライセンスは GPL v2 です。
NVDA は多くのアプリケーションに対応し、インストール不要で利用できるポータブル版、アドオンによる機能拡張など、さまざまな特長を備えています。
NVDA 日本語チームがリリースする NVDA 日本語版は、オーストラリアの非営利法人 NV Access がリリースする NVDA 本家版に日本語の音声エンジンと点訳エンジンを追加するなど、日本語 Windows 環境のための改良を行っています。
NVDA 本家版 2015.3 の主な改良点は、Windows 10 への暫定的な対応、ブラウズモードで1文字ナビゲーションを無効にできる機能(NVDA+Shift+スペース)、および不具合の修正です。
NVDA最新情報(本家版のバージョンごとの変更点)
https://www.nvda.jp/nvda2015.3jp/ja/changes.html
NVDA日本語版 2015.3jp の変更点
https://www.nvda.jp/nvda2015.3jp/ja/readmejp.html#toc65
Windows 10 の多くの機能について、NVDA は 7 や 8.1 と同等に機能しますが、現時点では一般的な NVDA ユーザーには Windows 10 の利用を推奨しません。
NVDA の Windows 10 対応に関する NV Access からの告知の日本語訳
https://d.nishimotz.com/archives/1833
最後に、開催日が近づいてきた「NVDAワールド」の最新のご案内です。
(ご案内 ここから)
NVDAワールド 2015 東京
2015年9月12日(土曜)
無料で使えるパソコン用スクリーンリーダーの導入から最新情報まで
NVDA (NonVisual Desktop Access)とは、無料で使えるオープンソースのWindows用スクリーンリーダーです。
合成音声や点字によるフィードバックを通して、視覚障害者が特別な出費をしなくてもWindowsパソコンを使えます。
NVDAは、世界中の各地域の個人・団体などの援助によりNV Access(視覚障害者であるMichael Curran氏を中心に作られた非営利組織)が開発しています。
NVDA日本語チームはこれまで、グローバルなNVDA開発コミュニティにおける日本語対応を担当しつつ、日本のユーザーに必要な機能を追加したNVDA日本語版の開発、日本国内におけるNVDAの普及啓発活動を行ってきました。
2015年7月に Windows 10 がリリースされ、無料アップグレードの提供が始まりました。
めまぐるしく変化するコンピューターとインターネットの世界、その中で挑戦を続ける NVDA の世界を、より多くの人にお知らせするために、昨年に引き続き「NVDA ワールド」を開催します。
今年の NVDA ワールドでは、最新の NVDA 日本語版 2015.3jp を使って、Windows や Web アプリなどの NVDA の操作の基本、NVDA にいろいろな機能を付け加えるアドオンの最新情報、職場における NVDA の活用方法を紹介します。
特別講演では、無料で利用できるオープンソースのオフィス統合環境 LibreOffice をご紹介します。
LibreOffice はワープロ、表計算、プレゼンテーションなどの機能を備え、Microsoft Office との相互運用性が高く、世界中からボランティアが参加するコミュニティによって活発な開発が行われています。
開発スタイルが NVDA と似ているだけでなく、LibreOffice の主要な機能はNVDA から使うことができます。
今回は LibreOffice の概要、 LibreOffice のアクセシビリティ、日本の翻訳チームの状況などについて、デスクトップ環境、印刷環境、国際化、翻訳を含むオープンソースソフトウェアの
幅広い分野で活動、著述、講演をしておられる、LibreOffice 日本語チームの おがさわら なるひこ 様にご講演いただきます。
NV Access に支援をしておられる日本財団様に、今年は日本のコミュニティのイベントにもご協力いただけることになりました。
NVDAにご興味・関心のある個人・団体・企業の皆様、ふるってご参加いただきますよう、ご案内申し上げます。
■ NVDAワールド 2015 東京 の概要
主催:NVDA日本語チーム
協力:日本財団 / 神奈川県ライトセンター視覚障害援助赤十字奉仕団 / 特定非営利活動法人 神奈川県視覚障害者情報雇用福祉ネットワーク
日時:2015年9月12日(土曜) 10時から17時
問合せ先: nvdajp@nvda.jp
会場:日本財団ビル (東京都港区赤坂1-2-2)
参加費:無料
定員:100人(予定)
参加方法:会場準備のため事前にお申し込みをお願いします。
後述の「募集」をご参照ください。
参加申込者が多数になった場合は受付を終了する場合があります。
開始時の誘導:9時30分から10時30分まで、東京メトロ 溜池山王駅 溜池交差点方面改札(銀座線の出口)からの誘導を行います。
終了時の誘導:イベント終了時に会場から東京メトロ 溜池山王駅への誘導を行います。(16時30分ごろと17時00分ごろの予定)
主催者から昼食の提供はありません。
■ 参加申し込み受付と募集
参加申し込みの受付および以下の募集を行っております。
NVDA日本語チームの connpass
http://nvdajp.connpass.com/event/18105/
または nvdajp@nvda.jp 宛のメールにてご連絡ください。
・一般参加者(誘導のご希望の有無をお知らせください)
・ライトニングトーク登壇者(一般参加者としてお申し込みください)
・当日の運営をお手伝いいただけるボランティアスタッフ
・ブース出展者(非営利活動グループ)
・ブース出展を伴う企業等のスポンサー(詳細は下記をご参照ください)
https://www.nvda.jp/2015/nvda-world-2015-tokyo-sponsors.html
■ プログラム
1. NVDA 日本語版 2015.3jp と Windows 操作の基本
講演:西本 卓也(NVDA 日本語チーム)
概要:NVDA 日本語版の最近の改良点と、Windows での文字の読み書きなど基本操作を紹介します。
時間:10時15分から11時00分
2. 就労における NVDA の活用
講演:村松 謙(ブラインドパソコンサポート)
概要:業務利用での NVDA のメリットや活用方法を紹介します。
時間:11時00分から11時30分
お知らせ
時間:11時30分から11時45分
昼休み
時間:11時45分から13時00分
主催者から昼食の提供はありません。近隣のお店をご利用頂くかご持参下さい。
3. NVDA による Web アプリの操作
講演:西本 卓也(NVDA 日本語チーム)
概要:Gmail などの Web アプリの操作を最新の NVDA を使って説明します。
時間:13時00分から13時45分
4. 特別講演:LibreOffice のアクセシビリティとコミュニティ
講演:おがさわら なるひこ(LibreOffice 日本語チーム)
概要:オープンソースのオフィス統合環境 LibreOffice の概要、アクセシビリティ、日本の翻訳チームの状況などについてご紹介します。
時間:14時00分から14時45分
5. NVDA アドオンの紹介
講演:野々垣美名子(NVDA 日本語チーム)
概要:インターネットを介して他のパソコンを遠隔操作できる「リモート」など、NVDA にいろいろな機能を付け加えるアドオンの最新情報です。
時間:15時00分から15時30分
6. 質疑応答
概要:NVDA日本語チームがNVDAについてのご質問にお答えします。
時間:15時45分から16時15分
7. ライトニングトーク
概要:5分程度の短い講演を4件程度募集します。登壇者は当日決定します。
時間:16時15分から16時45分
■ インターネット配信
インターネット配信を実施する予定です。
詳細はウェブサイト等でご案内します。
NVDA ワールド 2015 東京 の最新情報は下記でご確認ください。
https://www.nvda.jp/2015/nvda-world-2015-tokyo.html
■ 関連するイベント
このイベントの翌日の9月13日 (日曜)には AccSell Meetup 010 『Web制作者のためのNVDA入門』(主催:AccSell) が開催される予定です。
Web制作者の立場からNVDAに興味があるという方は、こちらのイベントもぜひご検討ください。
http://accsell.net/info/accsell-meetup010.html
(ご案内 ここまで)